

Recently, I ran into a gnarly issue with my Talos Kubernetes cluster: talosctl commands were failing with certificate errors, and the dashboard wouldn't load. The root cause? My SOPS age key and Talos secrets had drifted out of sync with what the cluster expected. Here's how I ruthlessly rolled everything back and got my cluster healthy again.
1. Diagnosing the Problem
First, I confirmed that the error was a TLS handshake failure, likely due to mismatched or rotated secrets. The specific error I encountered was:
failed to get node "192.168.8.173" version: rpc error: code = Unavailable desc = last connection error: connection error: desc = "transport: authentication handshake failed: tls: failed to verify certificate: x509: certificate signed by unknown authority (possibly because of \"x509: Ed25519 verification failure\" while trying to verify candidate authority certificate \"talos\")"This error indicates that the TLS certificate verification is failing because the certificate authority is unknown or the certificates have drifted out of sync. I checked my git history for both the talos/ directory and .sops.yaml to find a known-good state (in my case, the original bootstrap commit).
2. Extracting the SOPS Age Key from Kubernetes
Since my age key wasn't in git (for good reason!), I needed to extract it from the running cluster. I listed secrets in the flux-system namespace:
kubectl get secrets -n flux-systemI found the sops-age secret and extracted the key:
kubectl get secret sops-age -n flux-system -o jsonpath='{.data.age\.agekey}' | base64 -d3. Putting the Age Key Where SOPS Expects It
SOPS expects the key at ~/.config/sops/age/keys.txt, so I made sure it was there:
mkdir -p ~/.config/sops/age
echo "AGE-SECRET-KEY-1..." > ~/.config/sops/age/keys.txt
chmod 600 ~/.config/sops/age/keys.txt4. Regenerating Talos Configuration
With the right key in place, I regenerated my Talos secrets and configs:
talosctl gen config my-cluster https://my-cluster-endpoint:64435. Updating My Local Talosctl Config
I copied the generated config to where talosctl expects it:
cp talosconfig ~/.talos/config6. Testing the Dashboard
Moment of truth! I started the dashboard:
talosctl dashboardAnd it worked! I could see my nodes and cluster health again.
7. Verifying the Fix
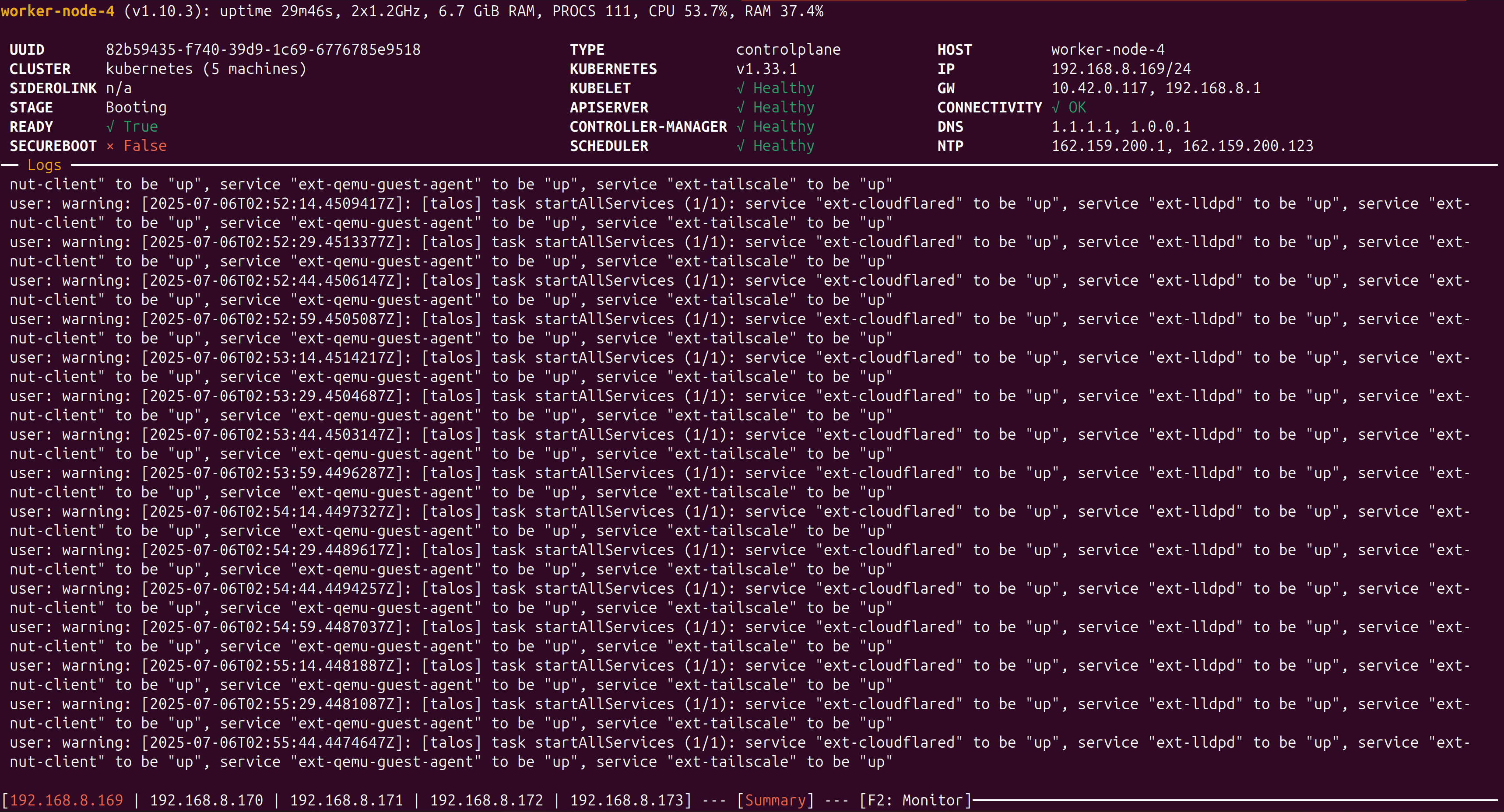
After following these steps, I ran talosctl dashboard again. This time, the dashboard loaded successfully, and all nodes reported as healthy. For example, here's what I saw for one of my nodes:
worker-node-4 (v1.10.3): uptime 29m46s, 2x1.2GHz, 6.7 GiB RAM, PROCS 111, CPU 53.7%, RAM 37.4%
UUID: 82b59435-f740-39d9-1c769785e9518
CLUSTER: kubernetes (5 machines)
STAGE: Booting
READY: True
SECUREBOOT: False
TYPE: controlplane
HOST: worker-node-4
KUBELET: Healthy
APISERVER: Healthy
CONTROLLER-MANAGER: Healthy
SCHEDULER: Healthy
Logs: Only normal service startup messages, no certificate or handshake errors.This confirmed that the TLS/certificate issue was resolved and my cluster was healthy again. The dashboard showed all nodes and services as expected.
Lessons Learned
- Always back up your age key somewhere safe, but not in git.
- If you lose the key, you can often recover it from the cluster's secrets.
- Regenerating Talos configs is painless if your secrets and keys are in sync.
This process saved me from a full cluster rebuild. If you're running Talos and SOPS, keep your keys safe and your configs versioned—you'll thank yourself later!
No comments?
There are intentionally no comments on this site. Enjoy! If you found any errors in this article, please feel free to edit on GitHub.